Claude Sonnet 4.6 is our most capable Sonnet model yet. It’s a full upgrade of the model’s skills across coding, computer use, long-context reasoning, agent planning, knowledge work, and design. Sonnet 4.6 also features a 1M token context window in beta.
For those on our Free and Pro plans, Claude Sonnet 4.6 is now the default model in claude.ai and Claude Cowork. Pricing remains the same as Sonnet 4.5, starting at $3/$15 per million tokens.
Sonnet 4.6 brings much-improved coding skills to more of our users. Improvements in consistency, instruction following, and more have made developers with early access prefer Sonnet 4.6 to its predecessor by a wide margin. They often even prefer it to our smartest model from November 2025, Claude Opus 4.5.
Performance that would have previously required reaching for an Opus-class model—including on real-world, economically valuable office tasks—is now available with Sonnet 4.6. The model also shows a major improvement in computer use skills compared to prior Sonnet models.
As with every new Claude model, we’ve run extensive safety evaluations of Sonnet 4.6, which overall showed it to be as safe as, or safer than, our other recent Claude models. Our safety researchers concluded that Sonnet 4.6 has “a broadly warm, honest, prosocial, and at times funny character, very strong safety behaviors, and no signs of major concerns around high-stakes forms of misalignment.”
Computer use
Almost every organization has software it can’t easily automate: specialized systems and tools built before modern interfaces like APIs existed. To have AI use such software, users would previously have had to build bespoke connectors. But a model that can use a computer the way a person does changes that equation.
In October 2024, we were the first to introduce a general-purpose computer-using model. At the time, we wrote that it was “still experimental—at times cumbersome and error-prone,” but we expected rapid improvement. OSWorld, the standard benchmark for AI computer use, shows how far our models have come. It presents hundreds of tasks across real software (Chrome, LibreOffice, VS Code, and more) running on a simulated computer. There are no special APIs or purpose-built connectors; the model sees the computer and interacts with it in much the same way a person would: clicking a (virtual) mouse and typing on a (virtual) keyboard.
Across sixteen months, our Sonnet models have made steady gains on OSWorld. The improvements can also be seen beyond benchmarks: early Sonnet 4.6 users are seeing human-level capability in tasks like navigating a complex spreadsheet or filling out a multi-step web form, before pulling it all together across multiple browser tabs.
The model certainly still lags behind the most skilled humans at using computers. But the rate of progress is remarkable nonetheless. It means that computer use is much more useful for a range of work tasks—and that substantially more capable models are within reach.
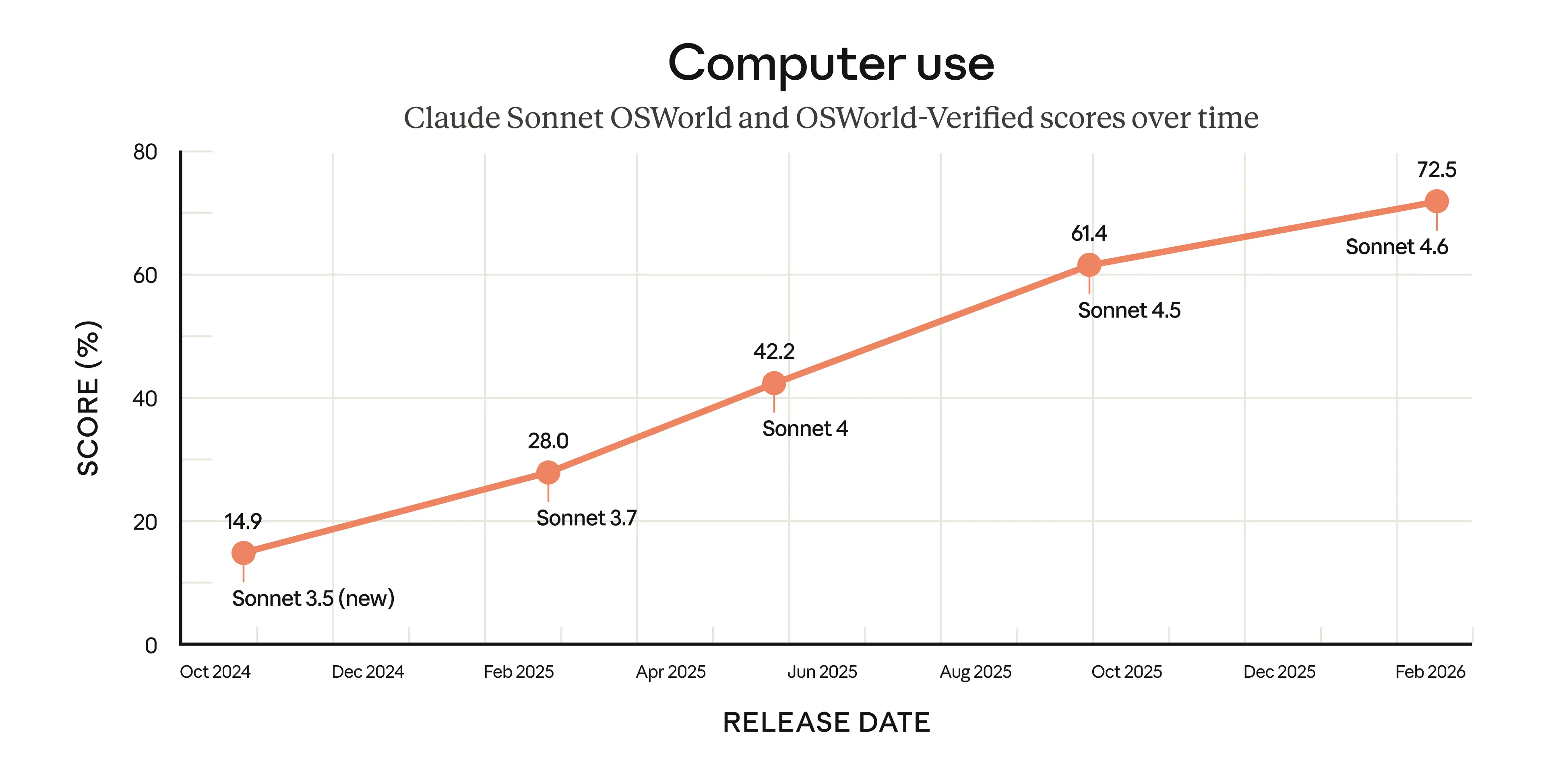
At the same time, computer use poses risks: malicious actors can attempt to hijack the model by hiding instructions on websites in what’s known as a prompt injection attack. We’ve been working to improve our models’ resistance to prompt injections—our safety evaluations show that Sonnet 4.6 is a major improvement compared to its predecessor, Sonnet 4.5, and performs similarly to Opus 4.6. You can find out more about how to mitigate prompt injections and other safety concerns in our API docs.
Evaluating Claude Sonnet 4.6
Beyond computer use, Claude Sonnet 4.6 has improved on benchmarks across the board. It approaches Opus-level intelligence at a price point that makes it more practical for far more tasks. You can find a full discussion of Sonnet 4.6’s capabilities and its safety-related behaviors in our system card; a summary and comparison to other recent models is below.
In Claude Code, our early testing found that users preferred Sonnet 4.6 over Sonnet 4.5 roughly 70% of the time. Users reported that it more effectively read the context before modifying code and consolidated shared logic rather than duplicating it. This made it less frustrating to use over long sessions than earlier models.
Users even preferred Sonnet 4.6 to Opus 4.5, our frontier model from November, 59% of the time. They rated Sonnet 4.6 as significantly less prone to overengineering and “laziness,” and meaningfully better at instruction following. They reported fewer false claims of success, fewer hallucinations, and more consistent follow-through on multi-step tasks.
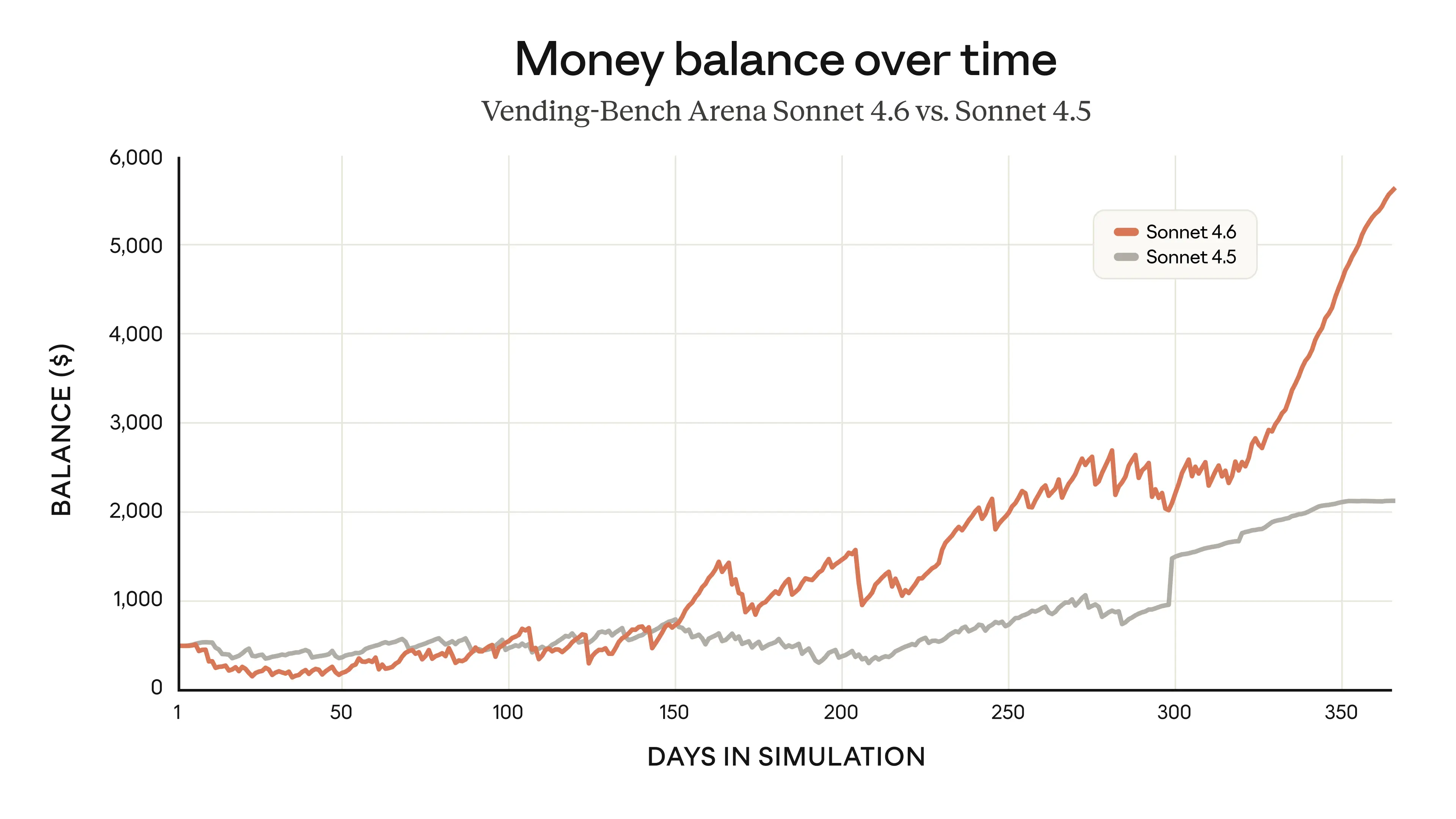
Sonnet 4.6’s 1M token context window is enough to hold entire codebases, lengthy contracts, or dozens of research papers in a single request. More importantly, Sonnet 4.6 reasons effectively across all that context. This can make it much better at long-horizon planning. We saw this particularly clearly in the Vending-Bench Arena evaluation, which tests how well a model can run a (simulated) business over time—and which includes an element of competition, with different AI models facing off against each other to make the biggest profits.
Sonnet 4.6 developed an interesting new strategy: it invested heavily in capacity for the first ten simulated months, spending significantly more than its competitors, and then pivoted sharply to focus on profitability in the final stretch. The timing of this pivot helped it finish well ahead of the competition.
Early customers also reported broad improvements, with frontend code and financial analysis standing out. Customers independently described visual outputs from Sonnet 4.6 as notably more polished, with better layouts, animations, and design sensibility than those from previous models. Customers also needed fewer rounds of iteration to reach production-quality results.
Claude Sonnet 4.6 matches Opus 4.6 performance on OfficeQA, which measures how well a model can read enterprise documents (charts, PDFs, tables), pull the right facts, and reason from those facts. It’s a meaningful upgrade for document comprehension workloads.
The performance-to-cost ratio of Claude Sonnet 4.6 is extraordinary—it’s hard to overstate how fast Claude models have been evolving in recent months. Sonnet 4.6 outperforms on our orchestration evals, handles our most complex agentic workloads, and keeps improving the higher you push the effort settings.
Claude Sonnet 4.6 is a notable improvement over Sonnet 4.5 across the board, including long-horizon tasks and more difficult problems.
Out of the gate, Claude Sonnet 4.6 is already excelling at complex code fixes, especially when searching across large codebases is essential. For teams running agentic coding at scale, we’re seeing strong resolution rates and the kind of consistency developers need.
Claude Sonnet 4.6 has meaningfully closed the gap with Opus on bug detection, letting us run more reviewers in parallel, catch a wider variety of bugs, and do it all without increasing cost.
For the first time, Sonnet brings frontier-level reasoning in a smaller and more cost-effective form factor. It provides a viable alternative if you are a heavy Opus user.
Claude Sonnet 4.6 meaningfully improves the answer retrieval behind our core product—we saw a significant jump in answer match rate compared to Sonnet 4.5 in our Financial Services Benchmark, with better recall on the specific workflows our customers depend on.
Box evaluated how Claude Sonnet 4.6 performs when tested on deep reasoning and complex agentic tasks across real enterprise documents. It demonstrated significant improvements, outperforming Claude Sonnet 4.5 in heavy reasoning Q&A by 15 percentage points.
Claude Sonnet 4.6 hit 94% on our insurance benchmark, making it the highest-performing model we’ve tested for computer use. This kind of accuracy is mission-critical to workflows like submission intake and first notice of loss.
Claude Sonnet 4.6 delivers frontier-level results on complex app builds and bug-fixing. It’s becoming our go-to for the kind of deep codebase work that used to require more expensive models.
Claude Sonnet 4.6 produced the best iOS code we’ve tested for Rakuten AI. Better spec compliance, better architecture, and it reached for modern tooling we didn’t ask for, all in one shot. The results genuinely surprised us.
Sonnet 4.6 is a significant leap forward on reasoning through difficult tasks. We find it especially strong on branched and multi-step tasks like contract routing, conditional template selection, and CRM coordination—exactly where our customers need strong model sense and reliability.
We’ve been impressed by how accurately Claude Sonnet 4.6 handles complex computer use. It’s a clear improvement over anything else we’ve tested in our evals.
Claude Sonnet 4.6 has perfect design taste when building frontend pages and data reports, and it requires far less hand-holding to get there than anything we’ve tested before.
Claude Sonnet 4.6 was exceptionally responsive to direction — delivering precise figures and structured comparisons when asked, while also generating genuinely useful ideas on trial strategy and exhibit preparation.
Product updates
On the Claude Developer Platform, Sonnet 4.6 supports both adaptive thinking and extended thinking, as well as context compaction in beta, which automatically summarizes older context as conversations approach limits, increasing effective context length.
On our API, Claude’s web search and fetch tools now automatically write and execute code to filter and process search results, keeping only relevant content in context—improving both response quality and token efficiency. Additionally, code execution, memory, programmatic tool calling, tool search, and tool use examples are now generally available.
Sonnet 4.6 offers strong performance at any thinking effort, even with extended thinking off. As part of your migration from Sonnet 4.5, we recommend exploring across the spectrum to find the ideal balance of speed and reliable performance, depending on what you’re building.
We find that Opus 4.6 remains the strongest option for tasks that demand the deepest reasoning, such as codebase refactoring, coordinating multiple agents in a workflow, and problems where getting it just right is paramount.
For Claude in Excel users, our add-in now supports MCP connectors, letting Claude work with the other tools you use day-to-day, like S&P Global, LSEG, Daloopa, PitchBook, Moody’s, and FactSet. You can ask Claude to pull in context from outside your spreadsheet without ever leaving Excel. If you’ve already set up MCP connectors in Claude.ai, those same connections will work in Excel automatically. This is available on Pro, Max, Team, and Enterprise plans.
How to use Claude Sonnet 4.6
Claude Sonnet 4.6 is available now on all Claude plans, Claude Cowork, Claude Code, our API, and all major cloud platforms. We’ve also upgraded our free tier to Sonnet 4.6 by default—it now includes file creation, connectors, skills, and compaction.
If you’re a developer, you can get started quickly by using claude-sonnet-4-6 via the Claude API.
Comments
However, if we frame the question this way, I would imagine there are many more low-hanging fruit before we question the utility of LLMs. For example, should some humans be dumping 5-10 kWh/day into things like hot tubs or pools? That's just the most absurd one I was able to come up with off the top of my head. I'm sure we could find many others.
It's a tough thought experiment to continue though. Ultimately, one could argue we shouldn't be spending any more energy than what is absolutely necessary to live. (food, minimal shelter, water, etc) Personally, I would not find that enjoyable way to live.
Now the question is: how much faster or cheaper is it?
Probably written by LLMs, for LLMs
Edit: Yep, same price. "Pricing remains the same as Sonnet 4.5, starting at $3/$15 per million tokens."
It feels like we're hitting a point where alignment becomes adversarial against intelligence itself. The smarter the model gets, the better it becomes at Goodharting the loss function. We aren't teaching these models morality we're just teaching them how to pass a polygraph.
I understand the metaphor, but using 'pass a polygraph' as a measure of truthfulness or deception is dangerous in that it alludes to the polygraph as being a realistic measure of those metrics -- it is not.
Just as a sociopath can learn to control their physiological response to beat a polygraph, a deceptively aligned model learns to control its token distribution to beat safety benchmarks. In both cases, the detector is fundamentally flawed because it relies on external signals to judge internal states.
A poly is only testing one thing: can you convince the polygrapher that you can lie successfully
> How long before someone pitches the idea that the models explicitly almost keep solving your problem to get you to keep spending? -gtowey
Being just sum guy, and not in the industry, should I share my findings?
I find it utterly fascinating, the extent to which it will go, the sophisticated plausible deniability, and the distinct and critical difference between truly emergent and actually trained behavior.
In short, gpt exhibits repeatably unethical behavior under honest scrutiny.
Regarding DARVO, given that the models were trained on heaps of online discourse, maybe it’s not so surprising.
Of your concern is morality, humans need to learn a lot about that themselves still. It's absurd the number of first worlders losing their shit over loss of paid work drawing manga fan art in the comfort of their home while exploiting labor of teens in 996 textile factories.
AI trained on human outputs that lack such self awareness, lacks awareness of environmental externalities of constant car and air travel, will result in AI with gaps in their morality.
Gary Marcus is onto something with the problems inherent to systems without formal verification. But he will fully ignores this issue exists in human social systems already as intentional indifference to economic externalities, zero will to police the police and watch the watchers.
Most people are down to watch the circus without a care so long as the waitstaff keep bringing bread.
It always has been. We already hit the point a while ag where we regularly caught them trying to be deceptive, so we should automatically assume from that point forward that if we don't catch them being deceptive, that may mean they're better at it rather than that they're not doing it.
Going back a decade: when your loss function is "survive Tetris as long as you can", it's objectively and honestly the best strategy to press PAUSE/START.
When your loss function is "give as many correct and satisfying answers as you can", and then humans try to constrain it depending on the model's environment, I wonder what these humans think the specification for a general AI should be. Maybe, when such an AI is deceptive, the attempts to constrain it ran counter to the goal?
"A machine that can answer all questions" seems to be what people assume AI chatbots are trained to be.
To me, humans not questioning this goal is still more scary than any machine/software by itself could ever be. OK, except maybe for autonomous stalking killer drones.
But these are also controlled by humans and already exist.
After all, its only goal is to minimize it cost function.
I think that behavior is often found in code generated by AI (and real devs as well) - it finds a fix for a bug by special casing that one buggy codepath, fixing the issue, while keeping the rest of the tests green - but it doesn't really ask the deep question of why that codepath was buggy in the first place (often it's not - something else is feeding it faulty inputs).
These agentic AI generated software projects tend to be full of these vestigial modules that the AI tried to implement, then disabled, unable to make it work, also quick and dirty fixes like reimplementing the same parsing code every time it needs it, etc.
An 'aligned' AI in my interpretation not only understands the task in the full extent, but understands what a safe and robust, and well-engineered implementation might look like. For however powerful it is, it refrains from using these hacky solutions, and would rather give up than resort to them.
Anthropic has a tendency to exaggerate the results of their (arguably scientific) research; IDK what they gain from this fearmongering.
As an analogue ants do basic medicine like wound treatment and amputation. Not because they are conscious but because that’s their nature.
Similarly LLM is a token generation system whose emergent behaviour seems to be deception and dark psychological strategies.
One of the things I observed with models locally was that I could set a seed value and get identical responses for identical inputs. This is not something that people see when they're using commercial products, but it's the strongest evidence I've found for communicating the fact that these are simply deterministic algorithms.
I don't know what the implications of that are, but I really think we shouldn't be dismissive of this semblance.
It was hinted at (and outright known in the field) since the days of gpt4, see the paper "Sparks of agi - early experiments with gpt4" (https://arxiv.org/abs/2303.12712)
https://claude.ai/public/artifacts/67c13d9a-3d63-4598-88d0-5...
https://bsky.app/profile/simonwillison.net/post/3meolxx5s722...
So if you don't want to pay the significant premium for Opus, it seems like you can just wait a few weeks till Sonnet catches up
You should always take those claim that smaller models are as capable as larger models with a grain of salt.
Something something ... Altman's law? Amodei's law?
Needs a name.
Yeah, but RAM prices are also back to 1990s levels.
Yeah it's really not. Sonnet still struggles while Opus, even 4.5 succeeds (and some examples show Opus 4.6 is actually even worse than 4.5, all while being more expensive and taking longer to finish).
The much more palatable blog post.
Interesting. I wonder what the exact question was, and I wonder how Grok would respond to it.